
Integrating SAP with your central nervous system of data significantly increases the value proposition of Apache Kafka and the Confluent Platform in your company’s IT infrastructure.
In our first blog post about integrating SAP with Kafka we presented a highly integrated solution for data replication using the standard ODP protocol and explained why there can’t be a unique solution to cover all SAP systems and processes, at least when complying with common software development standards. Instead, it is necessary to look at your individual use case to choose the most suitable integration solution.
In this blog post we introduce concepts and connectors supplementing the existing portfolio of SAP integration options based on the RESTful OData protocol.
What is OData?
OData is an open HTTP-based protocol created by Microsoft that facilitates the exchange of structured data across different system environments. Since version 4, OData is an OASIS Open standard that is approved by ISO/IEC JTC 1 as an international standard for Open Data Exchange.
SAP uses OData as a central technology in their new programming models, including the ABAP RESTful Application Programming Model (RAP) as well as SAP Cloud Application Programming Model (CAP). Therefore, OData is extensively used by SAP not only in various integration scenarios, but also in their SAPUI5 framework for building web applications to get and process data from SAP backend systems.
As the essential interface technology, OData plays a key role in SAP’s strategic direction, on-premise as well as in the cloud.
In contrast to other proprietary SAP interface technologies like RFC, BAPI, IDOC, BICS etc., OData provides an open API containing rich semantics. Those enable an almost infinite set of tools and programming languages to access SAP in a unified way. SAP systems already come with a huge set of pre-built OData APIs, which can be easily extended by simple activation for CDS-views and ODP data sources or by building customer specific APIs, e.g. in ABAP. This significantly increases security of your investments in API developments.
OData builds on the REST paradigm and extends it with additional rules that allow specifying a data model and a set of operations that can be performed on it. To structure the data, OData establishes a concept of typed objects that can have simple or complex properties, called entities. An OData service offers access to individual or collections of entities using the set of predefined Create, Read, Update, Delete (CRUD) or user-defined operations.
An obligatory and comprehensive metadata document that describes a service in a machine-readable manner creates the common understanding of an OData interface. It enables constructing OData interfaces whose underlying resources can be easily accessed by generic clients.
Key features of OData
Let’s have a closer look at the key feature supported by OData:
- Complex Business Objects
- Change Data Capture
- Batch Processing
- Packetization
Complex Business Objects
At its core, an OData service defines a data model that consists of entity types and relationships between them. For each entity collection, a service can offer CRUD operations to query and modify entities. In addition to that, further actions and functions on entity collections can be specified. Querying collections of data is supported by simply issuing HTTP Get-requests. Queries can be customized by applying query options like search, basic filter and special filters like top and skip, projection, sort order and expand. We focus on the expand option here, as it is expected to be least commonly known and the other options can be found with the same semantics in different SQL derivatives.
The expand option can be used to traverse the graph of the data model. Starting with an entity collection it defines the relationships to be followed to finally construct a directed tree of entities and relationships, represented as nodes and edges. Compared to SQL this would mean that expand defines the foreign keys to be followed by joining the corresponding tables. This does not seem to be very sophisticated but in the end, it enables us to process deeply nested structures of complex business objects.
INIT’s OData connectors have a built-in support for complex business objects by using the OData expand query option.
The OData V2 Source Connector allow the application of multiple expand paths for defining the final nested structure of a business object to be injected into Kafka.
In contrast to joining related datasets of a business object in the case of a pure two-dimensional data replication to Kafka, this heavily reduces complexity when it comes to processing complex business objects. The capability of processing deeply nested structures in the OData V2 Sink Connector by applying the OData’s deep-insert functionality makes it possible to insert complete business objects, created or modified outside of the SAP universe, into SAP systems.
Change Data Capture and Delta
Change Data Capture (CDC), sometimes called Delta, is a set of techniques for tracking data that has been altered. Changes in data can have various reasons e.g. deletions, updates or creations of database records. CDC takes a vital role when it comes to integrating data into an event streaming platform.
Some ETL and integration tools like SAP Data Services and SAP BW include functionalities to perform change tracking on the receiver side, that is in the integration tool itself. This can be achieved by repeatedly replicating data in a full extraction mode and comparing it to a replica of the full data set kept in some datastore of the integration platform. Despite being a simple procedure of doing change tracking and applicable to various kinds of sources, it has lots of drawbacks compared to real CDC-enabled sources and does not fit into a state-of-the-art event streaming architecture.
- Not scalable: First, this type of CDC is not scalable in most cases, as one needs to extract the same data sets regularly with a potentially infinitely increasing amount of data. There are some solutions for keeping the amount of replicated data constant, but the issue of high-volume data transfer and processing remains.
- Need for a complete replica: Another major drawback is the need for keeping a complete in-sync data replica in the integration platform. This gets even worse if the source allows for historical backdated changes of data that you want to keep track of. In this case, the data replica contains an insert-only like full history of changes.
- Other issues: In this article, we do not cover other issues like the complexity of executing reconciliations on multi-dimensional replicas in case of out-of-sync scenarios here. The conclusion is to do source-based CDC only for data that continuously changes.
OData specifies a mechanism to enable change tracking for individual OData services. It is an optional feature and describes the way deltas are offered to clients. The implementation of the CDC mechanism itself is part of the backend services and can have individual characteristics.
Change-Tracking in an OData can be initiated by issuing a GET-request for a feed of an entity set including the header field “Prefer” set to “odata.track-changes”. The response contains an initial set of data and a delta-link that can be used to request succeeding changes.
SAP provides an extensive set of CDC-enabled scenarios when it comes to using OData.
Besides the native OData change tracking support, which is available in SAP’s implementation of OData versions 2 to 4, SAP offers custom delta and event mechanisms with OData like push-subscriptions and business events, both supported by the connectors from INIT. For a detailed description of the subscription and notification flow refer to SAP help portal. After a connector has subscribed to a specific service entity set, the SAP gateway server uses a customized HTTP destination to send notifications about changed entities to an HTTP listener on the connector’s side. This mechanism limits the possibilities of parallelization done in Kafka Connect and should therefore only be applied to use cases where a reduced set of changes is expected.
A more recent approach from SAP is the support for business events. SAP provides a central place for documentation about OData services and business event APIs in the SAP API Business Hub. Business event APIs also follow a subscription-based model. A connector can subscribe to a set of business objects (SAP object types) and types of changes (task codes). It initiates the change tracking for these business objects and change events are persisted in an event queue for poll-based consumption by the respective connector instance. This type of event handling perfectly matches the design of Kafka Connect source connectors.
In addition to these OData native capabilities, SAP allows generating OData services on top of ODP sources, as we will explain later in more detail. The generated OData services automatically include a logical mapping of the delta capabilities of ODP to the change tracking mechanism of OData. Thereby you can use the OData V2 Source Connector to integrate CDC-enabled sources like ECC-extractors, SAP SLT trigger-based replication, SAP BW InfoProviders and ABAP CDS views enabled for delta consumption using a timestamp or built-in CDC.
Batch processing
When transmitting large amounts of data, redundant metadata in each OData request can have a huge impact on performance. This plays a minor role when the number of individual OData operations is small but gains importance as more consecutive OData operations are performed. In the same sense as a Kafka producer combines messages into batches for efficiency reasons in high data throughput scenarios, OData enables the combination of multiple OData operations into one single batch request returning one batch response containing the result and metadata for all individual operations in the exact same order. Even though, this way of micro-batching messages is always a tradeoff between transmission latency and throughput it cannot be compared to the traditional way of batch processing and does not break with Apache Kafka’s near-real-time paradigm.
Batching requests can have a huge impact on performance in integration scenarios.
Because OData supports batching for all kinds of operations, the overall count of HTTP requests for different consecutive operations can be decreased to only one HTTP request. This does not only save time and shrink the metadata overhead by reducing the number of roundtrips that would have been performed to establish the connection for each HTTP request but also minimizes the risk of losing data in an unstable network.
The OData V2 Sink Connector makes extensive use of batching. Before sending the data to the OData service endpoint, it buffers the received Kafka records for a brief time so that the accumulated Kafka records can be transformed and combined into OData batches of a predefined size. The maximum size of a batch as well as if batching is used at all for data transmission can be configured at connector startup.
The OData Business Events Connector batches requests when it is configured to enrich the business event data with the associated business object data. Normally, this implies that for each received business event entry there is one extra GET request needed for fetching the associated business object entry by its keys. With batching, consecutive GET requests for associated business object data are combined into one single batch request.
Packetization
In an optimistic scenario, continuous and equally distributed data streams are generated and processed as messages in Kafka in near-real-time. However, there are also situations in which a larger number of messages must be processed at the same time, for example, when initializing data pipelines taking into account historical data and in the event of temporary unavailability or full utilization of the systems involved. In such situations, it is essential that the quantity of messages to be processed can be divided into smaller packets so as not to have a negative impact on the parallelization and responsiveness of the system. Packetization has further positive aspects in situations where rebalancing has to be performed or reprocessing occurs during error handling.
In a distributed and parallelized environment such as Kafka, packaging ensures that individual tasks can react adequately to external influences.
OData has support for two different packaging modes: server-driven and client-driven paging.
As the name suggests, server-driven paging happens on the OData server side and can be initiated by a simple HTTP request header parameter. Each response will contain a next link for the client to be able to address succeeding pages or packets. This is the recommended option of pagination if supported by the corresponding OData service backend implementation.
Client-driven paging can be achieved by using the OData query parameters $skip and $top.
Both pagination options are supported by the OData V2 Source Connector and the page size can be further specified by configuration. Page addresses like next-link or skip and top values are part of the connector’s offset information for being able to perform offset-recovery in case of connector recovery or rebalancing and still guaranteeing exactly-once semantics. Furthermore, the connector is able to repeat single page extractions in case of processing abortions due to the fact that OData services comply to REST principles like statelessness. This reduces the necessary effort and amount of data processed during replication repetitions compared to OData queries without pagination.
OData for SAP systems
OData on top of ODP
The importance of the OData protocol at SAP is also reflected in the fact that Operational Data Provisioning (ODP)-based data extractions can be performed through OData services. ODP is SAP’s robust and field-tested framework for data extraction and replication. If you want to learn more about the ODP framework and INIT’s Kafka Connect ODP Source Connector, there is a blog post specifically on this topic.
By using OData on top of ODP, consumers benefit from the capabilities of both technologies. This combination provides access to the highly valued delta queues of the ODP framework via a unified, easy-to-read OData interface. Both full and delta extractions for various data sources such as BW InfoProviders and business content data sources are made available through these queues.
Another great feature of this combination is the possibility to resolve associations between multiple ODP sources in one single OData service. For a lot of business entities in SAP one needs to use multiple ODP sources for being able to extract a business object as a whole. To extract a sales order, for example, one needs to apply a bunch of data sources to extract header data, items, conditions and so on. This is mainly due to the fact that a sales order is constructed from multiple entities, but an ODP source is restricted to a two-dimensional representation of a single entity and 1:1-relations between them. An association between these ODP sources is implicitly defined by foreign key relations. These associations can easily be mapped into an entity association in a compound OData service joining all the ODP sources together and finally creating a meaningful and complete data extraction scenario.
To leverage the power of OData in combination with ODP, the SAP Gateway Foundation component is required as part of the ODP provider’s SAP NetWeaver system or as a separate SAP NetWeaver instance. Once this is in place, apart from the components communication and security setup, it is as simple as pressing a button in the SAP Gateway Service Builder (SEGW) to automatically generate the OData service and translate the underlying ODP structure into an OData model including the associated metadata document. Once activated, the service is ready to be consumed by the Kafka Connect OData V2 Source Connector, which comes with all the functionalities needed to extract data from an OData service that is based on an ODP source out-of-the-box.
Business Events Protocol on top of OData
SAP offers a protocol on top of OData for querying business events from S/4HANA on-premise or in the cloud. It is promoted as “the next generation digital events of SAP S/4HANA business objects” in the SAP API Business Hub, where you can find detailed information about the set of released business events. These events are built on top of SAP Business Event Handling (BEH) which is also used by SAP Enterprise Messaging, recently renamed to SAP Event Mesh.
The business events protocol involves multiple OData services and service calls, that’s why a separate source connector is provided by INIT to cover this scenario: The OData Business Events Source Connector. This connector enables near real-time streaming of SAP business events to Kafka by using standard APIs released by SAP without the need to install custom software to your SAP systems. The diagram below provides a high-level overview of the internal architecture of the connector.
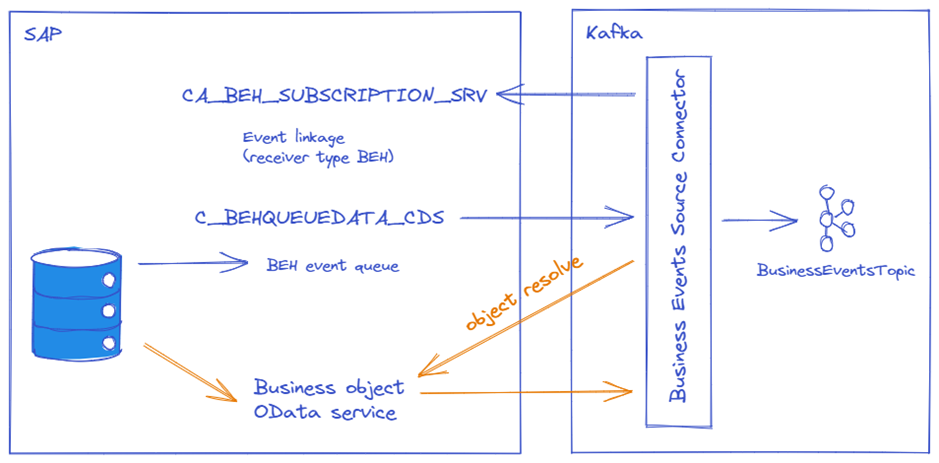
During startup, the connector creates a subscription for business objects and change types. This starts the change tracking process in SAP, which persists any matching changes of business entities in the BEH event queue. The connector is listening on the event queue to retrieve all relevant business events, which then are pushed to the Kafka target topic. SAP business events include information like the affected business object type, the kind of change, a unique identifier of the business entity, an event timestamp, and a unique event id, which is used to keep track of processed events to guarantee exactly-once delivery semantics.
As the event does not contain any business information besides the primary keys of a business entity, the connector offers configuration properties to enable a lookup of complete business entity information. This is achieved by querying OData services provided by SAP for the different kinds of business objects during the object-resolve phase.
The result is a message in Kafka which represents a complete business object event streamed in near-real-time out of an SAP system on-premise or in the cloud, without the need to set up or connect to additional event platforms like SAP Event Mesh.
INIT’s OData connectors
The connectors from INIT take advantage of the OData characteristics above to create Apache Kafka connectors that load data to or from OData endpoints with no need to write any service-specific code.
All connectors work out-of-the-box by configuration alone.
What makes INIT’s Kafka connectors unique compared to other solutions to integrate SAP with Kafka is the use of standard SAP Business APIs and the full integration into Kafka and the Confluent Platform by using Kafka Connect. Consequently, there is no need for maintaining a more complex and error-prone infrastructure, no need to install and maintain custom enhancements to your SAP system and at the same time delivering service guarantees that would be hard to achieve by relying on the low-level Producer/Consumer-API.
INIT has recently released version 1.3.3 of its Kafka connectors with a focus on enhancing the possibilities of integrating SAP with Apache Kafka. The ODP source connector being a robust piece of software, major feature enhancements and new connectors have been built around the OData protocol. The OData connectors are not restricted to be used with SAP, but they are highly optimized for use with SAP systems. The same applies for the use with the Confluent Platform, as the connectors are best used together with services like the Confluent Control Center, Schema Registry, ksqlDB and REST-API.
Demo: A closed loop of near-real-time sales order replication
In this demo use case, we use the Business Events Source Connector to replicate changes on sales orders in a SAP S/4HANA instance to Kafka. In a second step, as soon as a sales order event has been pushed to the target Kafka topic, the OData v2 Sink Connector uses the corresponding sales order as a template to generate a new sales order in SAP.

This is just a sample use case demonstrating the functionality of the connectors and can be adapted to your concrete business use case.
Download an evaluation version of our connectors from Confluent Hub and follow the documentation link on the connectors page for setting up a demo scenario like this with your own infrastructure. Confluent provides a docker image for easily setting up a standalone cluster of the Confluent Platform
First, a subscriber ID needs to be maintained in the SAP system by navigating through transaction SPRO → Cross-Application Components → Processes and Tools for Enterprise Applications → Business Event Handling → Subscriber → Create Subscriber ID.
For our demo, we used id KBES which is used later on by the Business Events Source Connector to subscribe to sales order events and to request events from the persistent event queue.
We are using a S/4HANA and gateway system here, so we have to make sure that all the following OData services provided by SAP are activated in the SAP Gateway:
- /sap/opu/odata/sap/CA_BEH_SUBSCRIPTION_SRV
The BEH subscription service is used for managing subscriptions. During connector startup, a subscription for sales order events will be created. After that, SAP captures all change events to sales orders in the event queue, even at times when the connector is not running, or when a connection problem arises. - /sap/opu/odata/sap/C_BEHQUEUEDATA_CDS
The BEH event queue service provides access to the events stored in the event queue. - /sap/opu/odata/iwfnd/CATALOGSERVICE;v=2
This is the catalog service offered by SAP to query the set of OData v2 services activated in your SAP systems. - /sap/opu/odata/sap/API_SALES_ORDER_SRV
This service will be used to query detailed sales order business information for the corresponding change event received through the business event queue.
You also need an SAP user account for authentication against your SAP systems and for granting access to the OData services and object data being used. If you need help setting up an SAP user account, ask your administration team.
For testing the connection to the individual SAP OData services, one can simply issue an HTTP request to the corresponding service path by e.g. using a web browser. Every OData service provides a metadata document that can be retrieved by appending path segment $metadata to the URL of the service.

The complete business object model for sales orders looks like this:
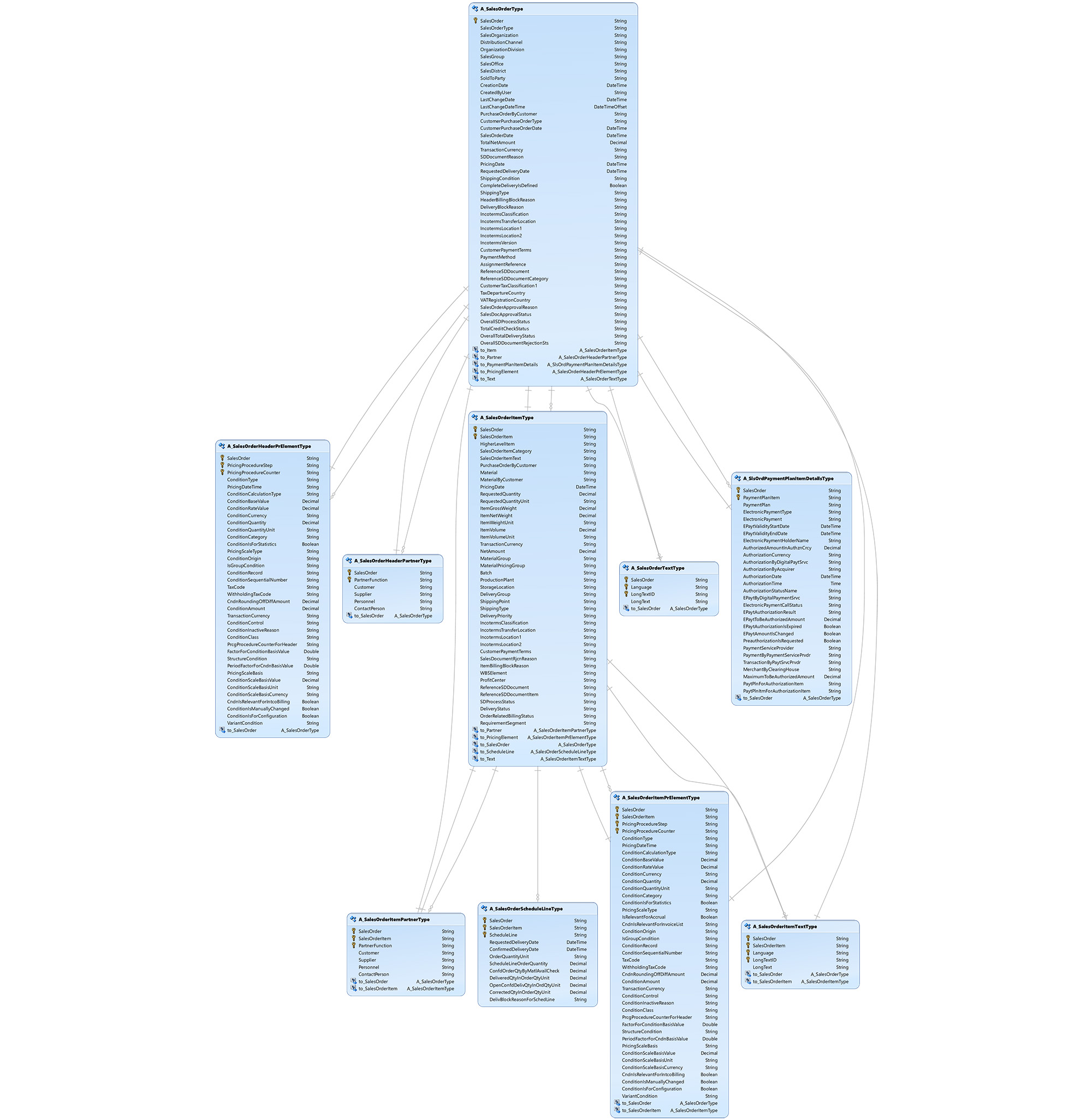
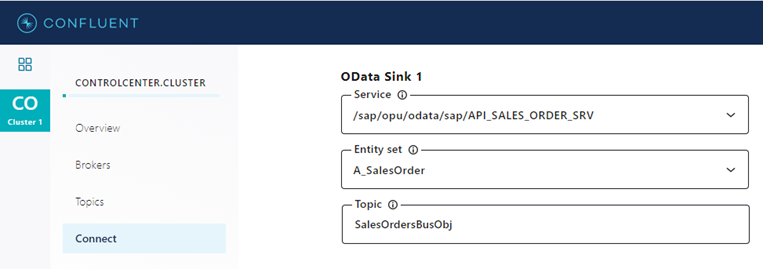
Here, we use the OData service /sap/opu/odata/sap/API_SALES_ORDER_SRV, the entity set A_SalesOrder and navigation property to_Item to publish sales orders and their corresponding items to Kafka.
Installing a new connector to your Confluent Platform can be done by either downloading the connector manually from Confluent Hub and copying it to the Kafka plugin path, or by using the Confluent CLI for an automated installation process. Please refer to the “Installation”-section of the “Getting started”-guide.
For setting up a new connector instance in Confluent Platform one can choose between the options to use the REST-API, ksqlDB or a more functional and convenient way using Confluent Control Center. We will use the Confluent Control Center here to set up the connector instances and to monitor messages and schemas for topics.
Each OData based connector first needs a configuration of the target destination. The following figure displays a sample destination configuration and the unique subscriber id for a Business Events Source Connector.
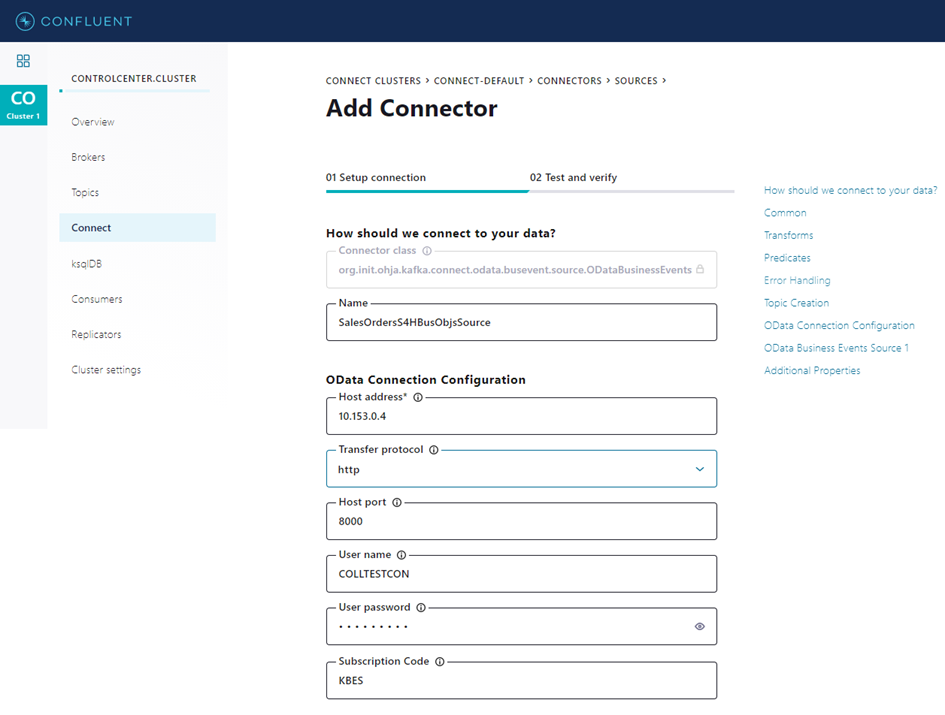
If the connection configuration is valid and a connection to the S/4HANA system can be established, the metadata service of the connector will fetch available object types, task codes, service names and entity information for value help and input validation.
The next figure shows the configuration for listening to change events for changed, created or deleted sales orders. As the connector should extract the complete business object instead of single basic event data, the standard OData service and entity type for sales orders has been selected for business object event resolution. By defining “to_Item” in the expand-list the sales order messages in the target topic will include order items besides basic sales order data.
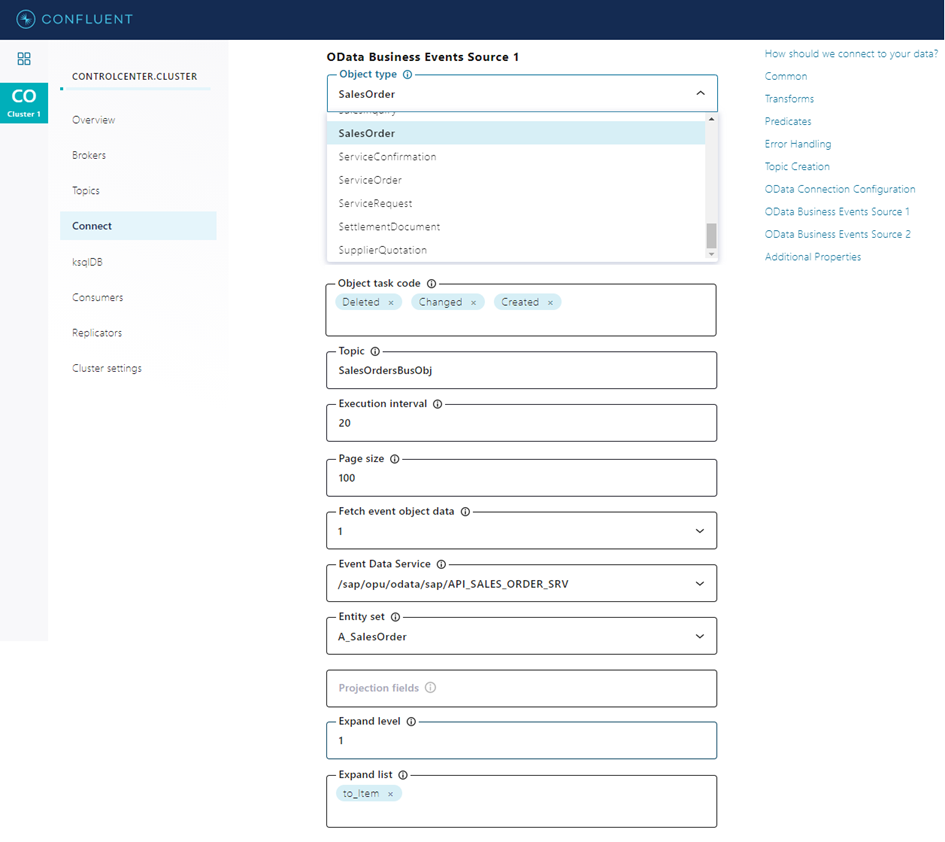
After successful validation of the configuration, the connector can be started at the push of a button and then waits for new sales order events.
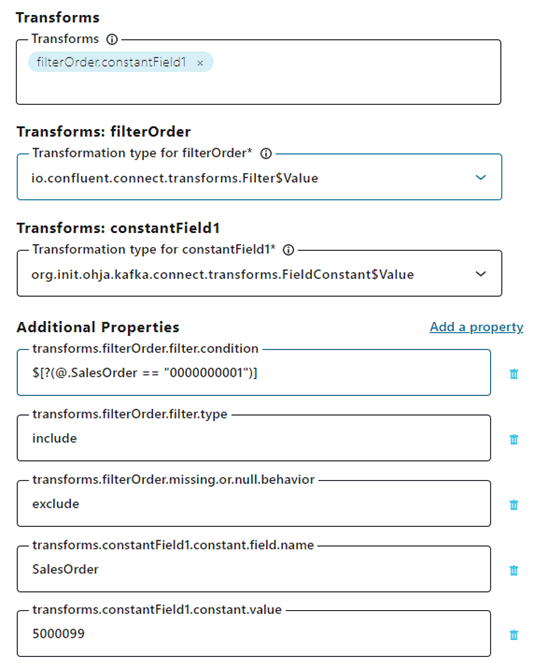
Before creating new change events in S/4HANA, we will also configure the OData Sink Connector, which will listen to the target topic of the Business Events Source Connector for new sales order events, apply simple SMTs to filter on sales orders with ID 1 and change the ID to 5000099 and write the copied sales order back to S/4HANA.

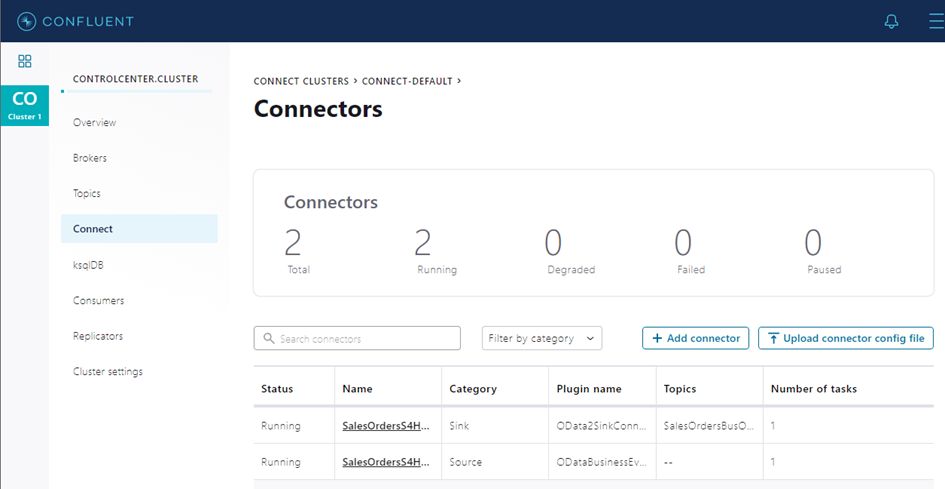
Both source and sink connector are up and running, as we can see on the Control Center status page.
We create a change for the existing sales order with ID 1 in the S/4HANA system by simply changing a free text field.
Now the whole magic begins:
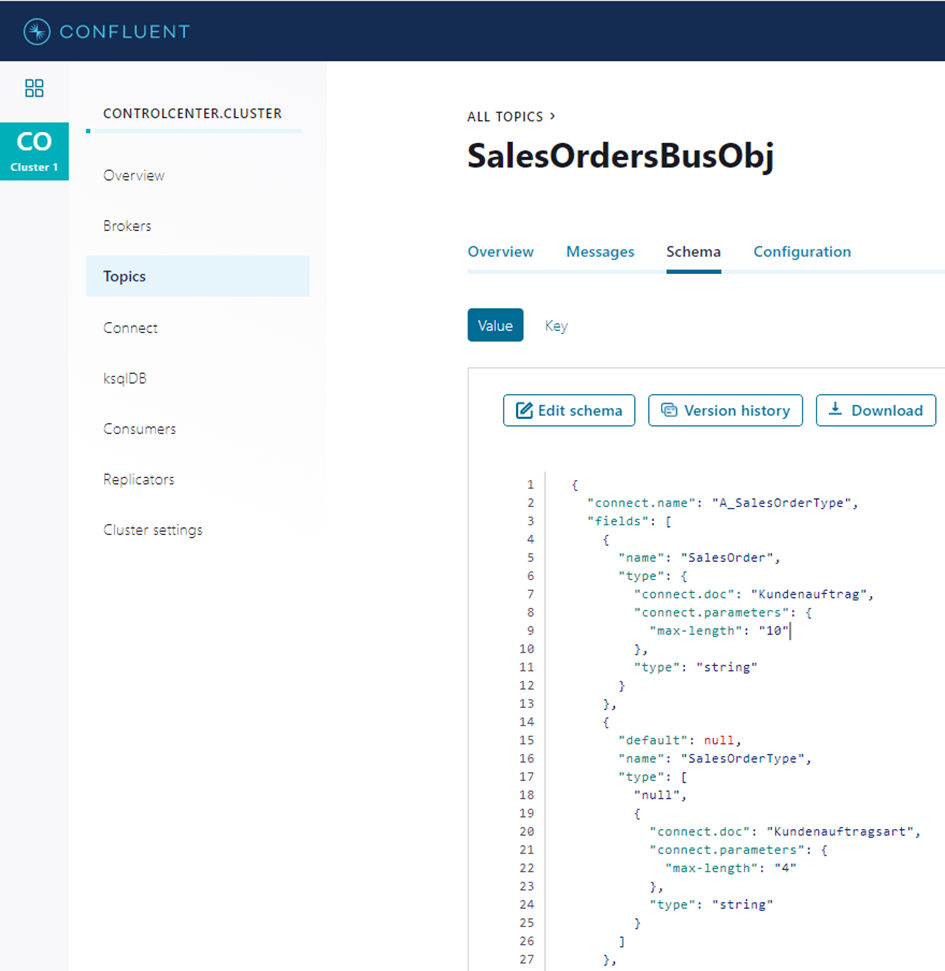
The Business Events Source Connector’s metadata service automatically creates a schema version for the SAP sales order object, finally published to the Confluent schema registry.
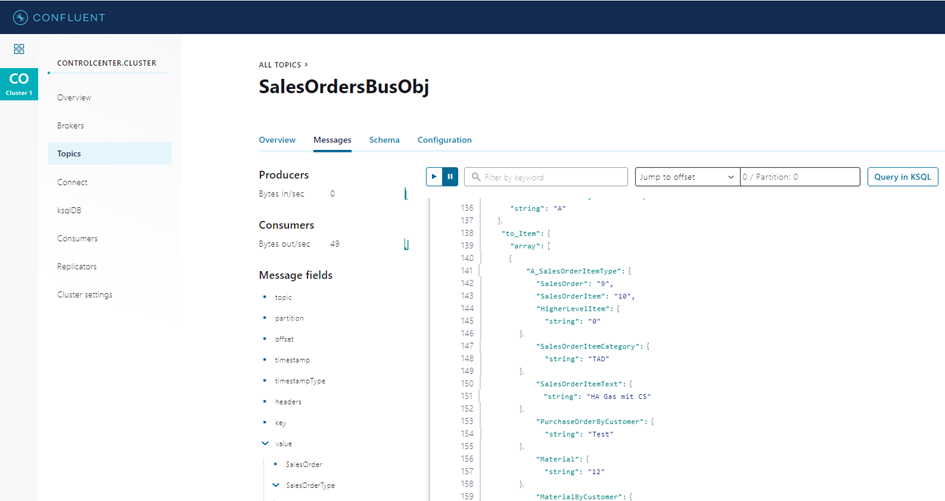
The Topics section of the Confluent Control Center can be used to inspect the details of the sales order message stored in the Kafka topic, including nested sales order items.

Besides sales order business object data, the connector adds basic information of the event to the Kafka messages.
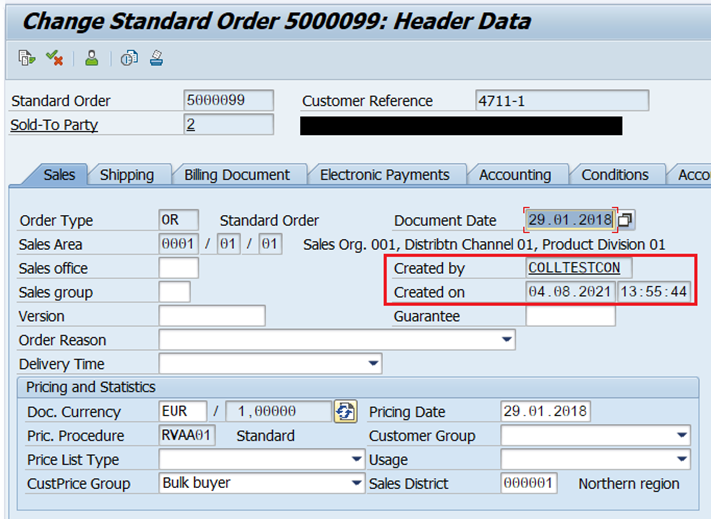
And finally, the newly created sales order with ID 5000099 was pushed and persisted in the S/4HANA system.
The demo didn’t focus on a specific business use case but demonstrates the possibilities of the connectors to extract business object information out of SAP for distribution and analysis via Kafka and changing and creating business objects in SAP by using external systems and services connected to Kafka.
Benefits & Limitations of the OData based connectors
Benefits
- OData is an open data protocol for RESTful APIs and not some proprietary SAP standard
- Support for SAP Business Events, Subscription and Notification Flow and OData change tracking
- Sink connector for publishing business object data to SAP
- Gold verified by Confluent for meeting standard integration requirements
- Natively integrated and compatible with Kafka Connect
- Support for Confluent Hub CLI, Control Center, Schema Registry, SMTs and converters for easy installation, configuration, administration, integration, and monitoring
- Proper data type mappings from OData data types and metadata to the internal Kafka Connect data model
- Compatible with different data type converters; changing the data format used to store messages in Kafka is just a matter of updating configuration settings (this has been tested with existing JSON and Avro converters)
- Heavy use of SAP metadata and therefore fully automated discovery of complex and nested schemas offered for consumption by Schema Registry
- Delivery semantics like at-least-once and exactly-once
- Back-off strategy in case of system downtimes or communication issues
- Out-Of-The-Box usage of released SAP OData services
- Support for complex and deeply nested data structures
- Usage of OData’s rich data model semantics
- Support for SAP on-premise or in the cloud
- Support for OData on top of ODP
- Integration with the REST API, ksqlDB and JMX Metrics
Limitations
- Separate connectors for OData version 2 and 4
- Performance limited by HTTP communication and data formats like AtomPub (XML) and JSON
- No support for nested query parameters in expanded entities
- No support for custom OData actions and functions besides CRUD
Outlook – What’s next?
The OData protocol comes in different versions, with versions 2 and 4 being the most relevant ones in the SAP ecosystem. Since version 2 is still widely used, especially in productive SAP systems, we first focused on creating OData-based connectors that support OData version 2. Because OData is the constant, future-proof interface technology at SAP that is becoming increasingly important, especially in the cloud environment, new OData connectors have been released to add support for all the new OData version 4 features to cover even more SAP integration scenarios. In parallel the OData connectors will be enhanced by OAuth capabilities complementing the existing username/password-authentication over HTTP(S).
As of the time of this writing there is a huge set of SAP solutions, third-party tools and connectors enabling the integration of SAP systems into Kafka, which makes Kafka a first choice for event-streaming your SAP business objects. This will greatly enhance the value proposition of your central nervous system of data.
The solutions portfolio from INIT is constantly being expanded by connectors with unique characteristics: tightest integration into Kafka, minimal dependencies, and infrastructure complexity, highly optimized for, tested with and gold verified for use with the Confluent Platform, robust and minimal TCO. The OData based connectors presented here share the same common characteristics as former connectors like the ODP-connector which come from the strict implementation of the Connect API and compliance with the Confluent gold verification requirements.
